W dzisiejszym odcinku Damian Niklewicz z ESKOM rozmawia z Janem Ćwierkiem, inżynierem pre-sales IBM z Ingram Micro, o nowoczesnej platformie IBM watsonx. Dowiemy się, czym dokładnie jest watsonx, z jakich modułów się składa oraz jak może pomóc organizacjom wdrażać generatywną sztuczną inteligencję, zarządzać danymi i spełniać wymogi prawne, takie jak te wynikające z AI ACT. Zapraszamy do posłuchania rozmowy o realnych zastosowaniach sztucznej inteligencji w biznesie – od zarządzania ogromnymi zbiorami danych po bezpieczne wdrożenia on-premise.
Damian Niklewicz: Cześć, tu Damian Niklewicz z ESKOM. Dzisiaj będziemy rozmawiali o sztucznej inteligencji firmy IBM, która nazywa się watsonx. A dzisiaj jest ze mną Jan Ćwierk, inżynier pre-sales IBM z Ingram Micro. Cześć Janku.
Jan Ćwierk: Cześć Damian, miło mi gościć dzisiaj u was w studio i dzień dobry państwu.
Damian Niklewicz: Od początku, co to jest ten watsonx?
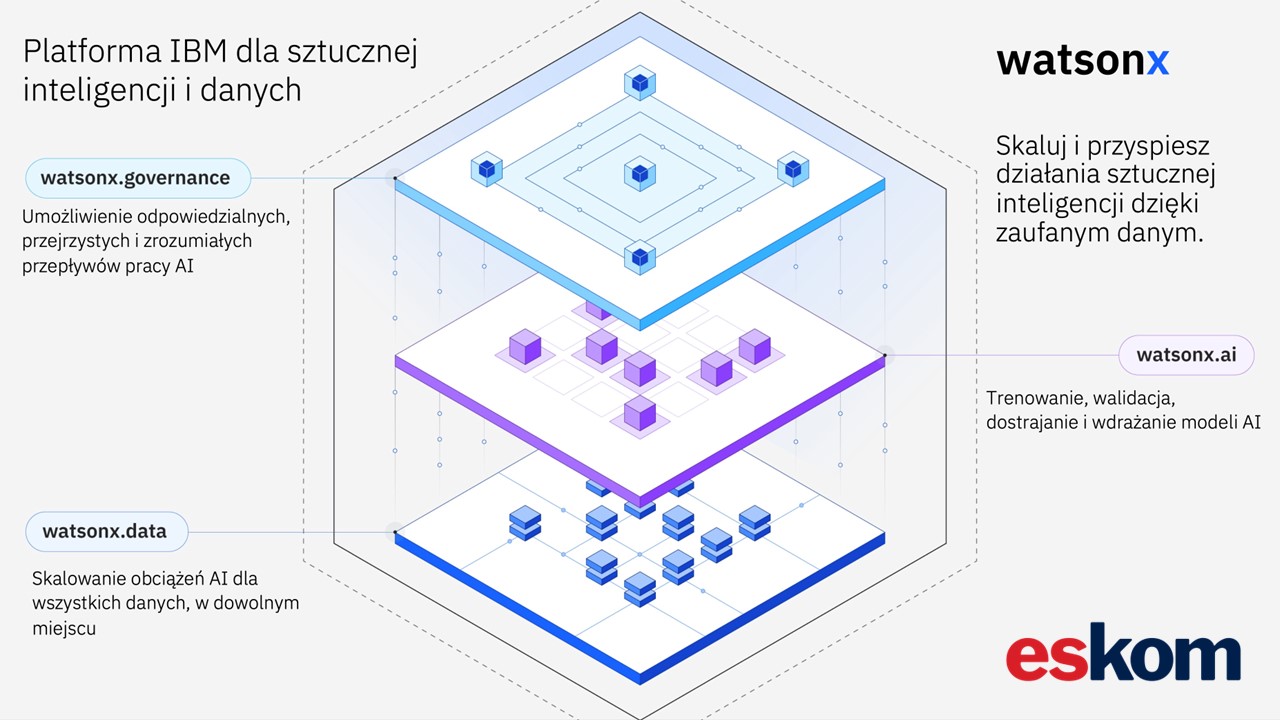
Jan Ćwierk: watsonx jest rozwiązaniem właśnie do sztucznej inteligencji, tak naprawdę to jest zaawansowana platforma, która ma w sobie trzy główne składowe. To jest watsonx.ai, watsonx.data i watsonx.governance, czyli ten pierwszy moduł jest ściśle związany z generatywną inteligencją. watsonx.data służy do tak naprawdę przechowywania danych, jest to swego rodzaju zaawansowana baza danych, o której myślę, że opowiem troszkę więcej za chwilkę, i watsonx.governance, czyli rozwiązanie, które pomaga nam monitorować użycie właśnie sztucznej inteligencji w naszej organizacji i spełniać wymagania regulacji, które wchodzą w życie. Generatywna sztuczna inteligencja czy sztuczna inteligencja sama w sobie jest dosyć nowym tematem i świeżym, i te regulacje cały czas się pojawiają, czy to lokalne, czy to chociażby w Unii Europejskiej.
Damian Niklewicz: No właśnie, jak regulacje, to jest AI ACT w Unii Europejskiej, ale jak mówimy o sztucznej inteligencji, to w zasadzie często się mówi: „My wdrażamy sztuczną inteligencję”. Nie wiem, wszyscy wiedzą co to jest, powiedzmy, ChatGPT, pewnie wiele osób go używa. Natomiast jak ma się do tej sztucznej inteligencji to rozwiązanie IBM? Do czego ono służy, jak może pomóc organizacjom i czym się na przykład różni od takiego powiedzmy ChatGPT?
Jan Ćwierk: To jest bardzo częste pytanie, czyli porównanie, a właściwie wyjście od takiego pytania, że sztuczna inteligencja to jest ChatGPT i co to tak naprawdę jest ten watsonx i co to jest właśnie taki ChatGPT. Już spieszę z odpowiedzią. Jeżeli chodzi o ten pierwszy moduł, o którym wspominałem na początku, czyli watsonx.ai, to rzeczywiście jest rozwiązanie, które pomaga nam wdrażać generatywną sztuczną inteligencję, czyli tak naprawdę modele językowe, które są od pewnego czasu coraz bardziej popularne właśnie dzięki ChatGPT, który stał się popularny już jakiś czas temu, ile, dwa, trzy lata temu? Myślę, że tak, już go używamy troszkę. OpenAI wypuszcza coraz to nowsze wersje tego dużego modelu językowego i w ramach platformy watsonx.ai możemy takie modele językowe również wdrażać w nasze rozwiązania. Tutaj mamy do wyboru tak naprawdę modele językowe dostarczone na przykład przez IBM, który tworzy własne modele językowe – to są modele z rodziny Granite – czy też możemy korzystać z modeli dostarczonych przez partnerów technologicznych IBM, na przykład Meta, czyli właściciela Facebooka. Ale też jeżeli potrzebujemy skorzystać z własnych modeli językowych, które na przykład żeśmy stworzyli lokalnie, jeżeli mamy takie zasoby, albo chcemy skorzystać z polskojęzycznych w pełni modeli językowych, takich jak Bielik, możemy oczywiście zainstalować, zaimplementować własny model językowy w rozwiązaniu watsonx.ai.
Na podstawie tych, czy przy użyciu tych modeli językowych, możemy tworzyć rozwiązania, które wspomogą naszą codzienną pracę, takie jak chociażby najpopularniejsze chatboty. Możemy również analizować dane, wyciągać informacje z naszych prywatnych danych czy przetwarzać je w sposób taki, żeby ułatwić i przyspieszyć naszą pracę. I co ważne, tak jak w przypadku ChatGPT, możemy uruchomić tę platformę zarówno w chmurze, jak i on-premise, czyli możemy korzystać lokalnie w naszej infrastrukturze, mając gdzieś z tyłu głowy przeświadczenie, że korzystamy z prywatnych danych w prywatnym środowisku i one są tutaj bezpieczne. Bo warto też o bezpieczeństwie pamiętać w przypadku sztucznej inteligencji.
Damian Niklewicz: Tak, nie wychodzi wtedy nic na zewnątrz.
Jan Ćwierk: Dokładnie.
Damian Niklewicz: Doprecyzowując, ChatGPT to jest model językowy, a IBM watsonx to platforma, na którą moglibyśmy na przykład takiego ChatGPT sobie też pobrać?
Jan Ćwierk: I tak, i nie. Zasadniczo tak, platforma. ChatGPT jako ChatGPT nie pobierzemy, aczkolwiek możemy wdrożyć rozwiązanie bazujące na modelach językowych które będzie analogiczne do przytoczonego właśnie ChatGPT.
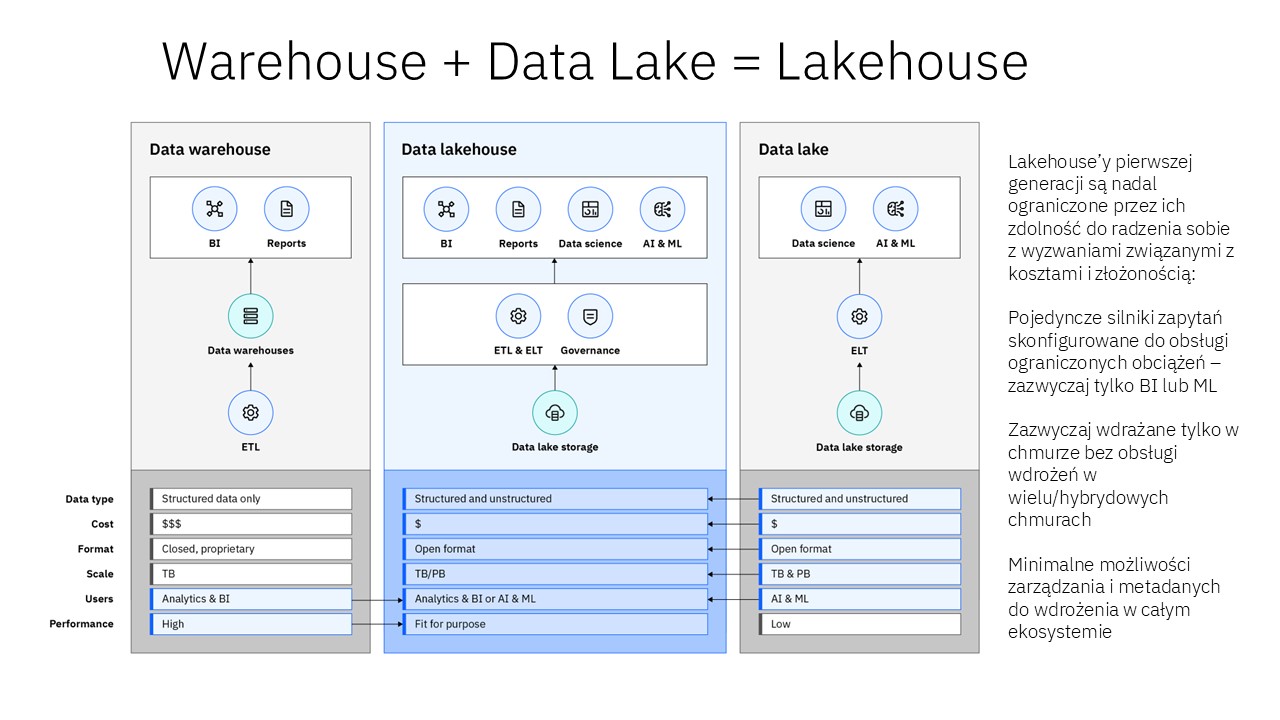
Damian Niklewicz: Ok, a po co aż trzy, po co ten ai, data i governance?
Jan Ćwierk: watsonx łączy ze sobą zarówno plusy Data Warehouse, jak i Data Lake, tworząc przy tym Data Lakehouse czyli rozwiązanie do przechowywania danych ustrukturyzowanych jak i nieustrukturyzowane, dzięki czemu możemy wykorzystywać te dane właśnie na potrzeby uczenia maszynowego czy sztucznej inteligencji czy Business Intelligence. Tutaj mamy wysoką dostępność danych dla rozwiązań opartych o sztuczną inteligencję.
Trzecim punktem, o którym możemy dzisiaj porozmawiać z rodziny watsonx, jest governance, czyli rozwiązanie do monitorowania użycia sztucznej inteligencji w naszej organizacji, dzięki czemu możemy w łatwy sposób okiełznać całą sztuczną inteligencję, modele językowe, które wykorzystujemy w naszej organizacji. Możemy weryfikować, w jaki sposób ta sztuczna inteligencja jest wykorzystywana, dzięki czemu, właśnie tak jak wspominałem na początku, będziemy w stanie spełnić wymogi prawne, które na nas czyhają. Tutaj też wspominałeś o AI ACT, czyli o regulacji, która została ogłoszona, została już opublikowana w Dzienniku Ustaw w Unii Europejskiej, która wchodzi w życie tak naprawdę w pełni w 2026 roku. Mamy jeszcze troszkę czasu, aczkolwiek ważne jest, że wchodzi w pełni, ponieważ ona będzie wchodziła fragmentami do naszego życia codziennego i już w styczniu mają wejść w życie pierwsze zapisy AI ACT, które już wymuszają na organizacjach wewnątrz Unii Europejskiej na stosowanie się do jego zapisów.
Damian Niklewicz: A propos tego AI ACT, to można już się zastanowić nad tym, jak zaudytować swoją sztuczną inteligencję. Jeśli ktoś ma IBM watsonx to będzie to dużo łatwiejsze z IBM governance. Natomiast warto o takim audycie pomyśleć
Jan Ćwierk: Pozwól, że ci jeszcze przerwę, bo chyba chciałeś kolejne pytanie zadać ale ważne, że w przypadku watsonx.governance możemy to zintegrować z już działającymi rozwiązaniami sztucznej inteligencji. Nie musi być to wszystko z rodziny watsonx, więc jeżeli mamy już jakieś wdrożone rozwiązanie sztucznej inteligencji, to możemy tutaj ten governance od IBM dołożyć.

Damian Niklewicz: Jasne, czyli IBM integruje się z różnymi technologiami, różnymi rozwiązaniami i można taki audyt pod AI ACT zrobić z IBM, nie zważając na to, jakiej platformy używamy. Jak mówimy o regulacjach, to spełniamy wymogi, zarządzamy czymś. A jak mówimy o zarządzaniu, to mi przychodzi do głowy taki problem, który spotyka wiele organizacji, które muszą działać na dużej ilości danych. Mamy powiedzmy takie czasy, że tych danych jest coraz więcej, z każdym kolejnym rokiem ich przybywa i ciężko się zarządza coraz większą ilością danych. Jak IBM pomaga przy tym?
Jan Ćwierk: I tutaj właśnie rozwiązaniem na przykład na duże ilości danych mamy watsonx.data. W sumie troszkę już o tym opowiedziałem, ale jeszcze raz w skrócie powiem, że watsonx.data jest rozwiązaniem, gdzie możemy przechowywać bardzo duże ilości danych i nie muszą być to dane ustrukturyzowane, mogą być też dane nieustrukturyzowane. Czyli wrzucamy wszystko tak jak leci do jednego worka, do tego lake’a, do lakehouse. Dokładnie. Dzięki czemu możemy też zapanować nad tymi danymi, możemy w prosty sposób zredukować bądź usunąć, czy uniknąć duplikacji danych i możemy zasilić dzięki temu w łatwy sposób również rozwiązania bazujące na sztucznej inteligencji.
Damian Niklewicz: Powiedzmy, że ktoś by się zastanawiał nad wdrożeniem takiego IBM watsonx, to od czego warto byłoby zacząć?

Jan Ćwierk: Jeżeli chodzi o wdrożenie samej platformy, to na pewno pierwszym krokiem musi być rozpoznanie potrzeb biznesowych klienta. Po takiej analizie biznesowej, po oczekiwaniach klienta moglibyśmy wybrać tak naprawdę produkt, który jest najlepiej zorientowany na potrzeby klienta i tutaj możemy uszyć na miarę rozwiązanie, które chcielibyśmy wdrożyć. Mamy trzy elementy platformy, czyli watsonx.ai, watsonx.data i watsonx.governance, i tutaj z takim offeringiem możemy zacząć.

Pierwsze pytanie, jeżeli chodzi już o wdrożenie, oczywiście po tej analizie biznesowej, po analizie wymagań, musimy się zorientować, czy klient oczekuje wdrożenia chmurowego, czy on-premise’owego, czy też rozwiązania hybrydowego, czyli część rozwiązania może być w chmurze, a część może być w naszej infrastrukturze. Tutaj platforma watsonx, czy IBM, jest na tyle elastyczny, że umożliwia każdą z tych opcji. Oczywiście wiemy, że niektórzy klienci nie pozwolą sobie na przykład wystawienie danych, czy analizę tych danych, czy generowanie odpowiedzi przez sztuczną inteligencję w chmurze, ze względu na profil działalności czy na branżę, w której funkcjonują. Dlatego też to rozwiązanie on-premise’owe jest jak najbardziej możliwe do uzyskania.
Następnym krokiem, myślę, że jest skalowanie tego rozwiązania – jak duże powinno być. Tutaj warto zaznaczyć, że rozwiązanie on-premise ma swoje plusy, ma minusy. Oczywiście dane są bezpieczne, tutaj myślę, że też troszkę porozmawiamy na temat bezpieczeństwa sztucznej inteligencji, ale jest też troszkę wymagań idących za takim rozwiązaniem on-premise, ponieważ trzeba mieć odpowiednią infrastrukturę do wdrożenia takiego rozwiązania, mam na myśli karty graficzne, czyli karty GPU, które są konieczne do uruchomienia takich modeli językowych.
Damian Niklewicz: Jasne, to zanim przejdziemy do bezpieczeństwa, to może powiedzmy o branżach, dla których taki IBM watsonx ma najlepsze zastosowanie?
Jan Ćwierk: Jeżeli chodzi o branże i klientów, którzy mogą skorzystać z funkcjonalności watsonx, to myślę, że tak naprawdę przekrój jest dosyć szeroki. Na pewno branże finansowe, ubezpieczeniowe, firmy sprzedażowe, marketingowe skorzystałyby z dobrodziejstwa generatywnej sztucznej inteligencji. Wszystko zależy tak naprawdę od tego, co chcemy uzyskać. Jeżeli mamy dosyć dużo klientów, musimy zapytania klientów, obsługę klienta jakoś zautomatyzować, to tutaj bardzo dobrym krokiem byłoby właśnie skorzystanie z generatywnej sztucznej inteligencji, żeby przyspieszyć obsługę klienta, obsługę mailową, obsługę zapytań, klasyfikację treści czy podsumowania zapytań, podsumowania umów kredytowych na przykład czy umów ubezpieczeniowych.
Wszystkie elementy, które mają w sobie albo obsługę klienta, albo generowanie nowych treści, albo jakieś takie wsparcie kreatywne. Mam na myśli na przykład firmy, które się zajmują marketingiem, ale też nie tylko firmy muszą się zajmować marketingiem, ponieważ tak jak ESKOM albo Ingram Micro, mamy wewnętrznie nasze działy marketingu i też myślę, że korzystamy z takiej generatywnej sztucznej inteligencji na co dzień, żeby jakoś naszą kreatywność pobudzić.
Damian Niklewicz: Nie, ja wszystko sobie piszę sam.
Jan Ćwierk: Czyli Ingram Micro, ESKOM tutaj nie korzysta.
Damian Niklewicz: Ale jakby wracając do tematu, to można w skrócie powiedzieć, że wszędzie, gdzie mamy dużo danych. Czyli nie zamykamy się na konkretne branże. Powiedzmy, są takie, które z założenia mają dużo danych, dużo umów na przykład kredytowych, ale też jest branża medyczna, tutaj też mamy obsługę pacjentów, też dużo danych.
Jan Ćwierk: Dokładnie tak, myślę, że to jest bardzo dobre też podsumowanie, czyli tam, gdzie mamy dużo danych i jest konieczna obsługa tych danych, czy obrobienie ich w jakiś przystępny dla użytkownika, dla klienta sposób, to tutaj możemy rzeczywiście rozwiązaniami sztucznej inteligencji na pewno coś zdziałać. Tylko warto też zaznaczyć, że platforma watsonx nie jest dla najmniejszych klientów, bo tutaj mamy jednak rozwiązanie skierowane do klientów większych.
Damian Niklewicz: Tak, wydaje mi się, że na etapie budżetowania to też wychodzi. Natomiast jak mówimy o danych dotyczących na przykład umów to tutaj zależy nam na tym, żeby nic nie wyciekało, wszystko było bezpieczne i pewnie taki klient banku bardzo nie chciałby, żeby sztuczna inteligencja uczyła się na jego danych i powiedzmy, czy w ogóle organizacje nie chciałyby, żeby na ich danych, które one udostępniają sztucznej inteligencji, to żebyśmy mogli na przykład uczyć konkurencję. To jak do tego podchodzi IBM?
Jan Ćwierk: W przypadku platformy watsonx to, że możemy uruchomić to rozwiązanie w naszej infrastrukturze, czyli on-premise, to jest jeden z głównych takich argumentów, gdzie my jako organizacja, która korzysta z platformy, rzeczywiście mamy pełną kontrolę nad danymi, które są analizowane i przetwarzane przez sztuczną inteligencję. Czyli nie wysyłamy tych danych nigdzie do chmury publicznej i na instancje, w których nie wiemy, co się dzieje z tymi danymi, czy one były usunięte po tym, jak zostały przetworzone, czy na przykład, tak jak powiedziałeś, służą do zasilania wiedzy dla konkurencji, dla innych klientów. Tylko operujemy wewnątrz własnej infrastruktury i korzystamy z tych danych w taki sposób, w jaki powinniśmy korzystać. Czyli te dane nigdzie nie są wysyłane i wykorzystywane przez inne organizacje.
W przypadku, kiedy korzystamy z rozwiązania watsonx chmurowego, to tutaj pewnie się nasuwa pytanie: „Okej, ale jak korzystamy z chmury, to czy te nasze dane są równie chronione tak jak w wypadku on-premise?”. Tak, w przypadku chmury IBM korzystamy z naszych zasobów, które mamy wydzielone, i te nasze dane są bezpieczne. Także mamy pewność, że nasze dane są naszymi danymi i nikt z nich nie korzysta w międzyczasie.
Damian Niklewicz: IBM gwarantuje, że nikt poza nami nie będzie na tych danych się uczył, kiedy korzystamy z rozwiązań IBM.
Jan Ćwierk: Mając prywatną infrastrukturę, prywatne rozwiązanie zamknięte pod kluczem, można powiedzieć, mamy pewność, że nikt nie będzie się uczył na tych danych. No chyba, że nastąpi pewnego rodzaju wyciek tych danych, co nie jest oczywiście kwestią platformy samej w sobie, ale zdarzają się takie sytuacje, że jakimś tam bokiem ktoś wejdzie do organizacji i może te dane wykraść, to wtedy nie jesteśmy w stanie ich ochronić. Ale rzeczywiście, pracując w obrębie naszej platformy, naszej infrastruktury, mamy pewność, że nasze dane są przetwarzane po naszej myśli.
Damian Niklewicz: Jak twoim zdaniem, jak przewidujesz, powiedzmy przyszły rok albo kolejne lata w rozwoju sztucznej inteligencji? Jak myślisz, w którą stronę może to pójść?
Jan Ćwierk: Myślę, że trend będzie trwał i rozwiązania sztucznej inteligencji będą wdrażane w wielu miejscach, w wielu branżach. Już teraz spotykamy się z rozwiązaniami opartymi na sztucznej inteligencji, tak naprawdę ta sztuczna inteligencja jest wszędzie, nawet w urządzeniach domowych, tam pralki czy zmywarki już wiedzą, jak korzystać z programów, bo nawet są obrandowane, że korzystają ze sztucznej inteligencji. Tak samo z generatywną sztuczną inteligencją, ona też jest coraz bardziej dostępna i coraz bardziej powszechna, i myślę, że ten trend będzie zachowany.
Patrząc na to, że jeszcze kilka lat temu modele językowe miały kilka milionów parametrów, a obecnie to jest już liczone w miliardach, widzimy, że ten trend i rozwój technologii jest po prostu dosyć dynamiczny. Wszystkie zasoby są skierowane w rozwój sztucznej inteligencji, dzięki czemu też uzyskujemy rozwiązania, które wspomagają nas w codziennej pracy, ułatwiają nam tę pracę i tutaj dostajemy narzędzia, które po prostu nas przyspieszają.
Damian Niklewicz: Czyli nasza produktywność rośnie. Świat rozwija się coraz szybciej.
Jan Ćwierk: Rozwija się coraz szybciej. Myślę, że nie zostaniemy tak prędko zastąpieni sztuczną inteligencją, bo trzeba mieć nad nią troszkę kontroli i też nie wszystko, co jest generowane, można brać za pewnik od razu. Jakiś tam element kontroli, sprawdzenia i weryfikacji tych treści musimy wprowadzić, bo to jeszcze chyba nie czas na pełne zastąpienie, żeby puścić tak przysłowiowe lejce generatywnej sztucznej inteligencji samopas. Myślę, że nie byłoby to zbyt spektakularne.
Jestem przekonany, że nasi partnerzy biznesowi, partnerzy IBM, tacy jak ESKOM, są w stanie wesprzeć klienta na każdym etapie projektu, poczynając od analizy biznesowej, przez wdrożenie, aż po szkolenie klienta na etapie końcowym i utrzymanie takiego rozwiązania. Ponieważ tutaj kompetencje, myślę, że są najważniejsze i to nasze partnerstwo od lat już pokazuje, że jesteśmy w stanie takie projekty przeprowadzić i szczęśliwie doprowadzić do końca.
Damian Niklewicz: Dziękuję ci Janie za super wyjaśnienia i bardzo ciekawą rozmowę. Jak widać, wdrożenie platformy IBM to nie tylko technologia, ale również i strategia, i plan. Z tobą mam nadzieję, że zobaczymy się wkrótce i będziemy mogli rozmawiać o ciekawych rozwiązaniach IBM dalej.
Jan Ćwierk: Dziękuję Damian za zaproszenie i również ciekawą rozmowę i mam nadzieję do zobaczenia i do usłyszenia.
Damian Niklewicz: Cześć wszystkim.
Jan Ćwierk: Cześć.
